上一篇文章中我们学习了无监督学习中不含概率假设的部分,但是使用MLE进行预测仍然是非常重要的预测方法,而之前对于无标签数据是通过假设距离 作为衡量因素,概率学习则是通过假设给定 z,ϕ 情况下的 P(x∣zi,ϕ) 去实现的,为了更加方便计算,我们会使用EM algorithm 去简化计算MLE的过程,但我们通过计算发现这只适用于训练数据量较大的情况,而对于数据维度比较大时,我们会使用Factor analysis 去代替分析进行特征提取。
Mixture of Gaussian#
仍然考虑对于给定 (x1,x2,...xn) ,将其分成k类的问题
对于之前Naive Bayes 的时候,我们是做出 zi ~ Ber(ϕ) 的假设,对于 P(xi∣z,ϕ) 可以通过训练数据去学习,而对于Mixture of Gaussian,我们需要对于 P(xi∣z,ϕ) 做出更多的假设才能得到相应的模型。
Assumption
- zi ~ Multinomial(ϕ1,ϕ2,...ϕk) ,其中 Σi=1kϕi=1
- x∣zi,ϕ ~ N(μi,Σi) ,这个是合理的假设,对于一般的数据分布都是正态分布
从而代入
l(ϕ,x)=log(Πi=1mP(xi,ϕ))=log(Πi=1mΣj=1kP(xi∣zj,ϕ)P(zj∣ϕ))=Σi=1mlog(Σj=1kP(xi∣zj,ϕ)P(zj∣ϕ)))
How to solve the parameters?#
如果我们已知 P(z∣xi,ϕ) 在supervised learning 中可以通过训练数据去得到,此时的参数为
ϕjμjΣj=m1i=1∑m1{z(i)=j},=∑i=1m1{z(i)=j}∑i=1m1{z(i)=j}x(i),=∑i=1m1{z(i)=j}∑i=1m1{z(i)=j}(x(i)−μj)(x(i)−μj)T.
而在此时,我们仍然是使用假设的方法:

求解Mixture of Gaussian
对于每一个循环中我们假设了 P(zi=j∣xi,ϕ)=Σi=1kP(xi∣zi=j,ϕ)P(zi=j,ϕ)P(xi∣zi=j,ϕ)P(zi=j,ϕ) ,并保持它在该循环不变,更新相应的参数,最后该表达式会收敛到确定的参数值。
通过以上的步骤我们大致的得到了一个结果,但是至于为什么会收敛以及EM steps 的一般形式呢?
EM algorithm#
数学原理#
Jenson Inequality:E(f(x))>f(E(x)) 对于任何的凹函数成立,反之符号相反
琴生不等式 在高中数学竞赛中是一个常识性的结论,对于其数学证明可以参见《数学奥林匹克小丛书高中卷——均值不等式与柯西不等式》第一章的例题部分。
几何直观 上,以一个二次函数为例,就是对于凹函数,如果控制x1+x2的值不变,想要将 f(x1)+f(x2) 的值更大,那么两者就要离得越远
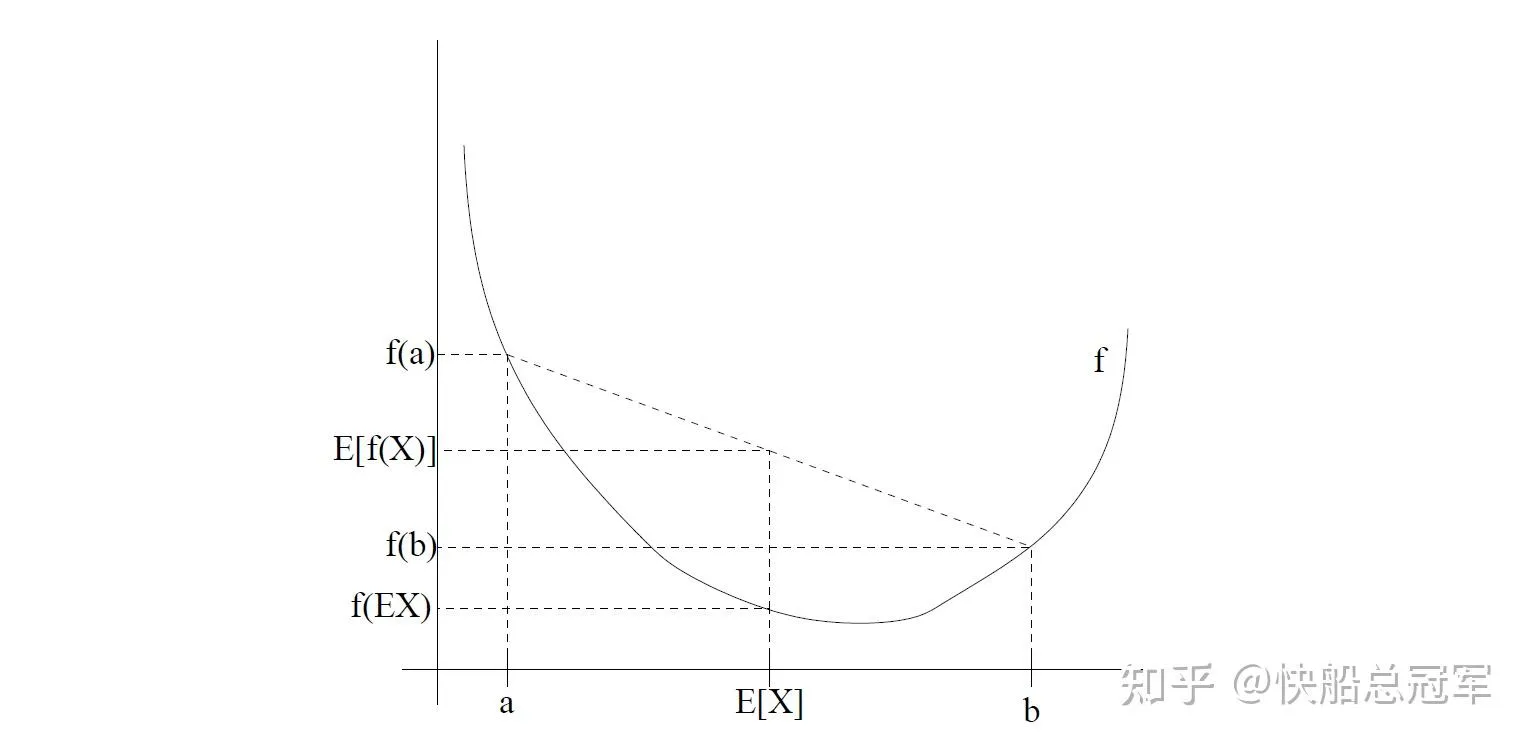
Jenson inequality
EM algorithm:#
假设对于给定 xi , zi 值的分布 Qi(z),ΣzQi(z)=1 ,则
i∑logp(x(i);θ)=i∑logz(i)∑p(x(i),z(i);θ)=i∑logz(i)∑Qi(z(i))Qi(z(i))p(x(i),z(i);θ)
由于log函数为凸函数,而我们想要求MLE的最大值,使用Jenson不等式,有
∑ilogp(x(i);θ)≥∑i∑z(i)Qi(z(i))log(Qi(z(i))p(x(i),z(i);θ))
使用右侧的函数作为损失函数更加方便计算。
对于 Qi(z) 怎么取呢?我们希望对于 Qi(z(i))p(x(i),z(i);θ) 方便计算,最好为常数,那么就有
Qi(z(i))p(x(i),z(i);θ) ~c,结合 ΣzQi(z)=1 有
\begin{align} Q_i(z^{(i)}) &= \frac{p(x^{(i)}, z^{(i)}; \theta)}{\sum_z p(x^{(i)}, z; \theta)} \\ &= \frac{p(x^{(i)}, z^{(i)}; \theta)}{p(x^{(i)}; \theta)} \\ &= p(z^{(i)} | x^{(i)}; \theta) \end{align}
因此一般的EM algorithm的步骤 为
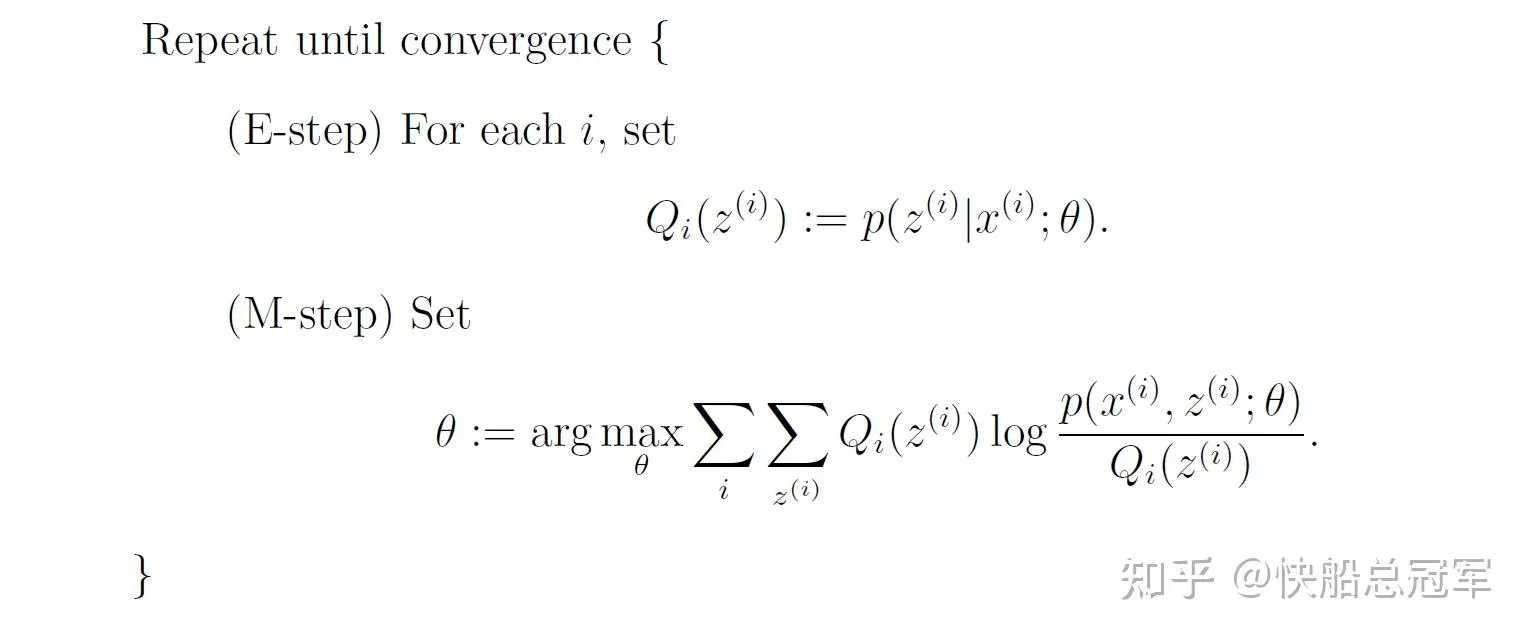
EM algorithm
Validate with Mixture of Gaussian#
在Mixture of Gaussian 中,我们就是通过Bayes 公式去计算 p(zi∣x,ϕ) 作为zi的分布,然后通过Jesnson不等式简化后的损失函数(同样是基于概率假设),使得对于每一个iteration之后,损失函数损失更小,参数更加接近真实值且反映出数据状况。(具体计算过程请见Problem Set 3 Solution )
Factor analysis#
当数据维数大于数据的量时,由线性代数知识可知 (x1,x2,...xm)∈Rn 这些向量全部是线性相关的,则对于Mixture of Gaussian时有
Σj=∑i=1mwji(x(i)−μj)(x(i)−μj)T 行列式的值为0,此时在计算Gaussian的概率分布时 ∣Σ∣0.51=01 这显然矛盾!这说明我们需要根据此时的数据特点做出些别的假设
预处理: 通过均值以及整体的方差将数据归一化
核心假设:
- 对于标签 z∈Rd 表示认为标签为d类,同之前的总类数,有 z ~ N(0,I) (已经归一化了)
- 数据与标签成线性关系 x=μ+λz+ϵ ,噪声 ϵ ~ N(0,Φ)
仍然是使用EM algorithm
E step: 计算 P(zi∣xi,ϕ) ,由我们的假设,这是z和x的一个条件概率分布,也是正态分布,即有 zi∣xi,μ,λ,Φ ~ N(μzi∣xi,Σzi∣xi) ,我们通过协同概率去计算
对于条件概率我们有
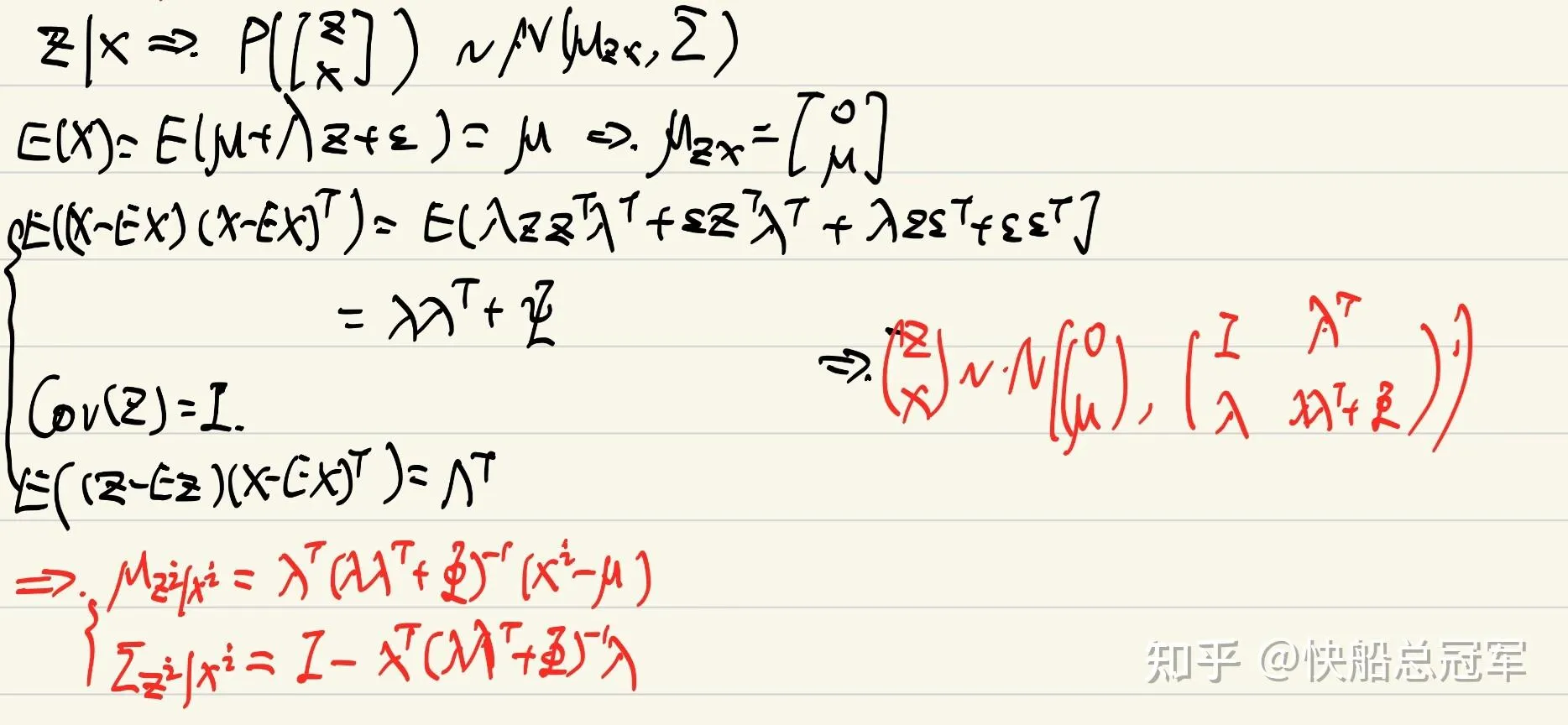
带入已知条件得到条件概率

M-step: 这里仍然是暴力计算,得到结果为
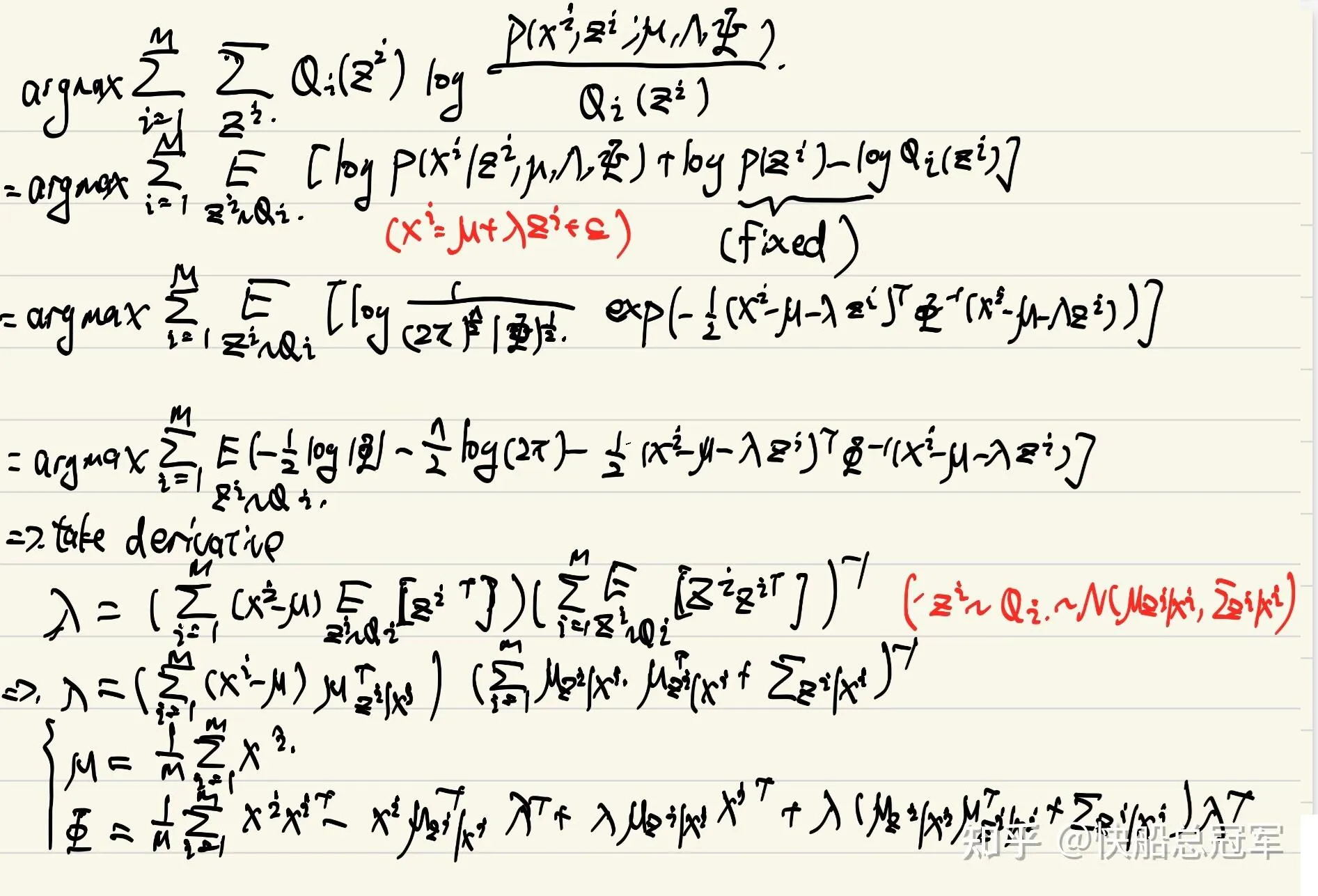
从而每个iteration迭代参数即可。对于Factor analysis可以将数据抽象成若干个特征,但是同时也可以反映不同特征的相关性,这点对于PCA是没有的。
在cs229中我们简要的学习了几种的无监督学习的算法,无论是无概率还是有概率,都是一定的假设,包括特征值,距离,高斯假设,以及对于特征的分布的假设并由此可以进行分类,特征提取任务。但个人感觉最重要的还是对于信息量 的问题。如果缺少了标签信息,就必须要一定的假设去补充,同样的,我们还可以添加一些别的假设,通过类似的方法,也可以得到新的无监督学习算法。
