
CS230 C4W2: 经典卷积神经网络设计及CNN常见应用
CS230 C4W2: 经典卷积神经网络设计及CNN常见应用
CS230 C4W2-5: 经典卷积神经网络设计及CNN常见应用
之前我们探讨了什么是CNN,CNN的基本架构,但是设计CNN 取得最好的效果也非常重要。经典的CNN设计可以给我们提供这种设计的思路,而当我们知道如何设计一个CNN之后,在落实到具体的项目(人脸识别,图像生成,物体识别)时又分别有些独特的地方,下面将会一一进行介绍
经典CNN设计#
我们的CNN所需要调整的超参数主要有:卷积核的大小,channel数量,连接关系。而在经典的CNN则告诉我们
- 卷积核大小&channel 数量 :对于相邻层之间保持整体的信息量不变(LeNets5,AlexNet)
- 通过池化层来调整整体的信息量 ,并且比例大概为1/2左右(VGG-16)
- 如何进行串联 (ResNets)
- 1*1卷积核以及由此引发的并联关系 (GoogleNets)
对于LeNets5,AlexNets, VGG-16都是比较早期的网络,如果我们将一个CNN看成是一堆电阻的连接的话,那么这三者就是研究每一个电阻的设计的。
LeNets5#
废话少说,直接上网络图

如果我们想要计算它的参数的话,可以发现,对于前面卷积层的参数是非常少的,对于一个有c个channels的,卷积核 的卷积层,参数大小只有 ,但是全连接层的参数量可以说是非常的大。于是对于全连接层,我们一般会下降到几百几千的时候再使用FC
同时LeNets的设计使用了** Conv=>Pool=>Conv=>Pool…**的结构,Pool可以认为是整合信息,而Conv是提取信息,对于两者交替进行的设计也是非常重要的想法。
** LeNets5:**规定了CNN的整体结构,Conv&Pool交替+最后的FC
AlexNets#
AlexNets在CNN设计上没有特别突出的地方,但它是真正意义上的第一个深度神经网络,总共有60M的参数,总共10几层,可以在ImageNets上实现1000种图片分类正确率80%的效果。在15年的时候是非常牛B的。
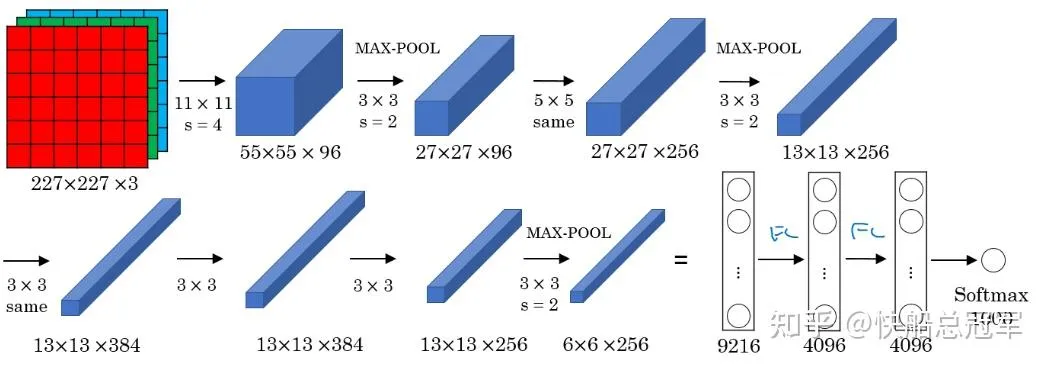
AlexNets的关键不止于此。往年的神经网络基本都是使用sigmoid&tanh(比较符合人脑神经元的激活条件),但是AlexNets为了训练更深的网络,使用了非常多的** ReLU**函数,同时它还是第一个使用多个GPU进行训练的神经网络,就凭以上几点,AlexNets就以及非常NB了
AlexNets: ** ReLU,深度NN,GPU training**
VGG16#
VGG-16也是一个非常大的网络,在人脸识别种也有比较广泛的应用。它的创新点** 使用padding这个东西,卷积层不改变图像大小,只在池化层将整体大小缩小一倍**。同时它还提出了使用小卷积核来代替大卷积核的想法。
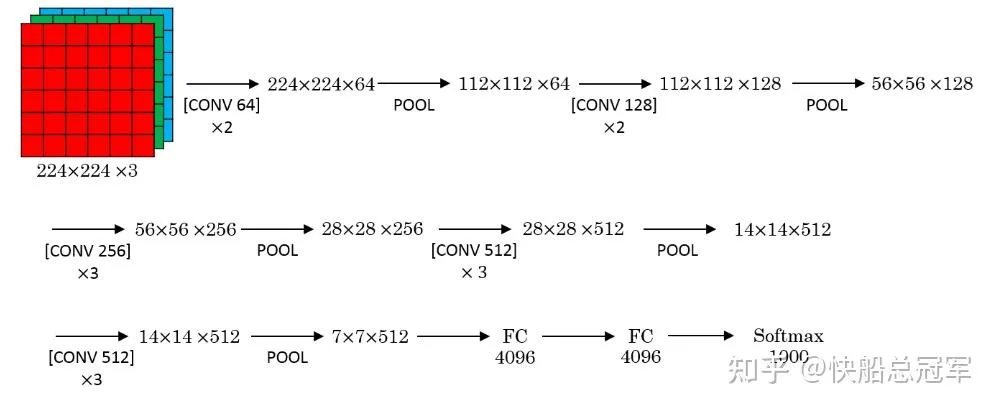
之前的LeNets之类的都使用了很多 的卷积核,但是VGG16却告诉我们使用 的卷积核也可以,不仅增加网络的深度,同时也减少了参数量。同时它还告诉了我们对于整体信息而言,需要保持以信息量的观点去设计网络
小卷积核使得提取信息从小到大均可,这增加了网络的可迁移性,为之后的 Transform Learning提供了基础
以上都是卷积核&通道的设计思路,但是对于更深的网络,又该怎么办呢?以上网络都是一条路走到黑,如果我们想要将网路串联起来怎么办呢,ResNets以及GoogleNets就解答了这个问题
ResNets#
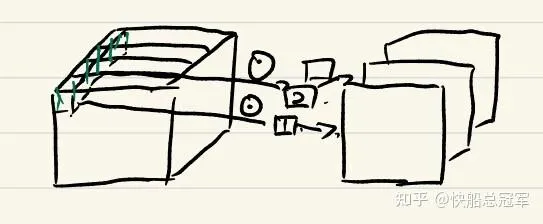
ResNets个人认为是一个里程碑式的东西,之前所有的网络都是一条路走到黑,当层数上升的时候就会导致严重的梯度爆炸/消失现象,但是ResNets的skip式的连接结构就完全解决了这一情况

由图可以看到,我们的ResNets的一个Block中为conv1=>conv2,output=conv2+conv1 的结构,而其好处就是即使网络深度更深,也不会导致梯度消失。
使用以上的skip path的方法我们就可以训练更深的网络 。
在ResNets的原始论文中(pass)中,我们可以对于skip path上不是直接连接过去的,而是使用了两种不同模块——Identity Block块(直接相加,保持网络稳定)以及Conv Block(卷积操作),最后我们设计了ResNet-18,34,50,101,152层的网络,其大小分别为11M,21M,25.5M,44.5M,60.2M
卷积核#
在介绍GoogleNet之前,有一个常见的操作叫 卷积核。
卷积核看上去没有什么用处,但是每一个 卷积核相当于对所有在这个位置上的图片的特征进行重组,从而对于图片特征进行调整 ,而如果我们使用多个 卷积核,那么就是可以对于通道数量进行调整
Google Net#
Google Net启发与我们对于卷积核的大小而言, 都是一种选择,甚至池化层也是一种选择,与其思考该如何将进行选择,我们可以考虑将这些东西全都拍到一块
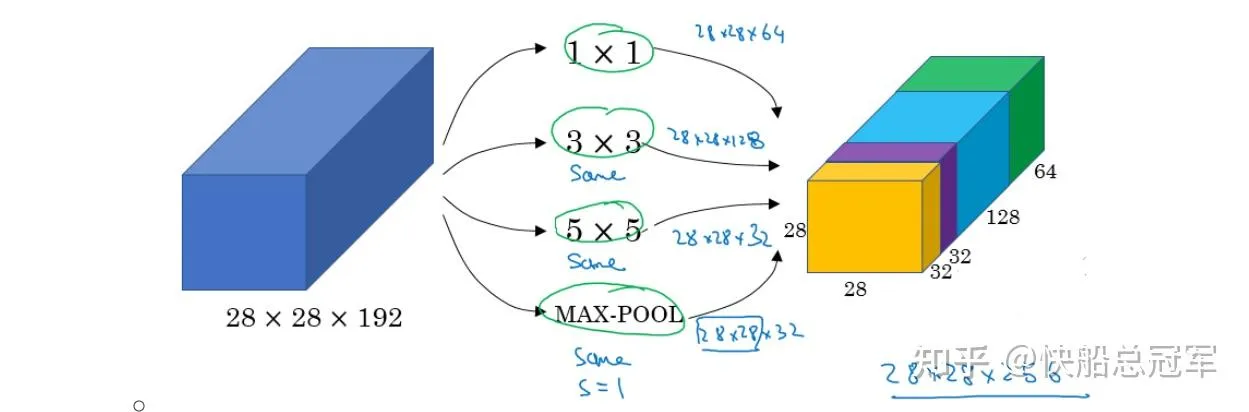
即为通过padding保持在使用 个 卷积之后图片大小不变,将所有的 都拍到一起,形成一个同样大小的东西。
于是google net使用若干个不同的这样的inception模块并组合起来,发现最后的效果非常好。
综上所述,我们对于设计网络的时候可以考虑对他们进行transfer training,即为固定网络的前面若干层,直到最后的几层换成我们自行设计的网络进行训练。而我们自己设计的时候需要考虑** 信息量的传递关系,可以通过inception block以及skip path的途径**来加深我们的网络并提升性能。这些都是可以考虑的方案。